
A Shift to Parallel AI: Embracing Mercury Diffusion Language Models


At Continue, we've built our platform on a fundamental belief: developers need the freedom to choose the right AI tools for their specific workflows. This philosophy is why we've designed an open, modular architecture that can quickly integrate new innovations as they emerge in the AI-native development space.
Understanding the Diffusion Approach
The recent introduction of diffusion-based language models (dLLMs) like Mercury Coder from Inception Labs represents exactly the kind of technological shift our architecture was designed to accommodate. While traditional autoregressive models have powered remarkable advances in AI coding assistants, they face inherent speed limitations due to their sequential generation approach.

Just as diffusion models can transform random noise into a clear mountain image through iterative refinement, Inception Lab's dLLM Mercury Coder transforms noisy text into clean, precise code in parallel rather than sequentially.

Mercury Coder refines code from noise to clean implementation in just 14 iterations, compared to the 75+ iterations required by traditional models.
Maintaining Developer Flow State
For developers, the difference between a 500ms and 100ms response time isn't just a technical specification—it's the difference between maintaining your creative flow and constantly being interrupted. When your AI assistant takes too long to respond, each suggestion becomes a context switch that breaks your concentration.
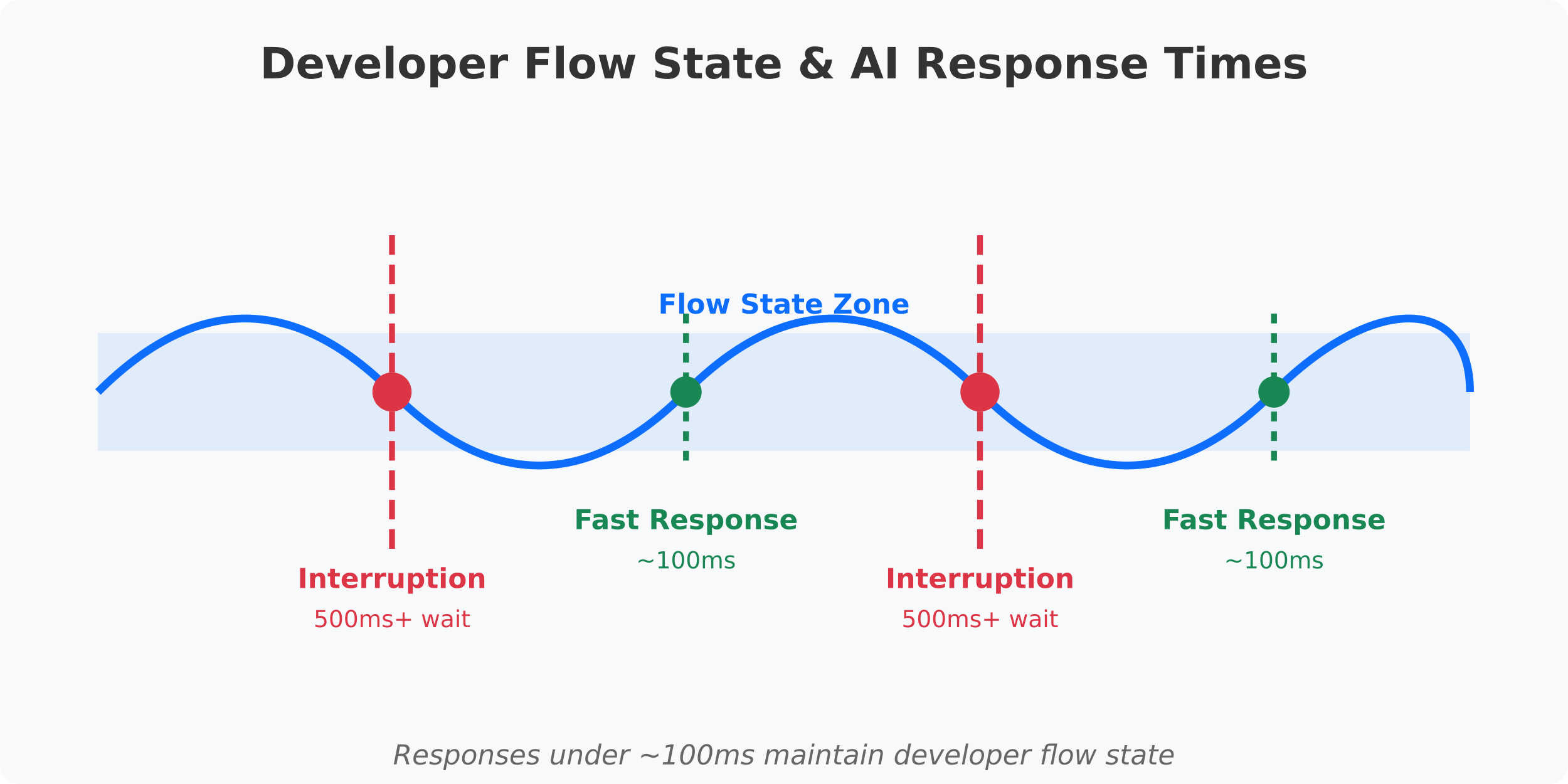
Diffusion language models provide responses fast enough to maintain your flow state rather than interrupting it. Notably, these models are able to achieve these blazing fast speeds while maintaining the quality of traditional LLMs.
What makes Continue valuable in this rapidly evolving landscape is our ability to quickly integrate new models and approaches as they emerge. Unlike closed systems that force developers into a single way of working, our platform lets you experiment with different models and find the combination that best amplifies your unique workflow.
Your Custom AI Assistant, Your Choice
As the AI-native ecosystem continues to evolve, we remain committed to providing a platform where developers can craft custom assistants that truly amplify rather than automate their work—regardless of which models or approaches they choose to include.
Mercury Coder is now available through the Continue Hub and can be easily integrated into your existing workflows.
Inceptions dLLMs are just one example of the ongoing innovation in AI coding assistants. Continue's modular architecture ensures you'll have access to these innovations as they emerge, with the freedom to adopt what works best for your specific needs and preferences.
We invite you to try Mercury Coder today through the Continue Hub. You can learn more about how to sign up for Mercury Coder and experience for yourself how parallel, diffusion-based generation can transform your development workflow with ultra-fast responses that keep you in your creative zone.
Join other AI-native developers on our Discord [https://discord.com/invite/vapESyrFmJ] to share your experiences with different model architectures and discuss how you're customizing your AI assistants for optimal workflow.