
Instant Apply


“UX risk”
Over the last year and a half of developing features that users didn’t like, finding out they didn’t like them, and then trying again, we’ve built a better idea of what will and won’t fly. Among the biggest predictors is what I call “UX risk”. [0]
In our internally-formed UX lingo, this basically means the amount of energy that the user can expect to lose from the LLM messing up, something like
\[ p\cdot (t + a) \]
where \(p\) is the probability that the LLM fails, \(t\) is the time from user request to response, and \(a\) is any additional “annoyance” caused in the case of failure. [1]
Consider some examples: Autocomplete is a great feature because it quickly predicts small pieces of text, and is unobtrusive when wrong. This means that \(p\), \(t\), and \(a\) are small. On the other hand, OpenAI’s new model, o1-preview, is impressive but doesn’t provide great UX because it takes some time and doesn’t stream (\(t\) is large), and it is so far quite difficult to guess which tasks it will be uniquely suited to solving (\(p\) is large).
When users learn that a feature is risky (high latency, low probability of success), they stop using it, and unfortunately (but understandably) their trust is hard to win back. This isn’t entirely new as a concept, but it’s certainly more pronounced in LLM-centric products.
While we don’t always prioritize work with a closed-form equation, we recently began to realize that there was a clearly outsized opportunity to reduce risk within Continue: a better “Apply” button.
Why is Apply so important?
The chat sidebar is a very low risk feature. Given that you can start reading immediately while it streams, \(t\) is small. And \(p\) is typically fairly high: when generating code, even if the LLM isn’t perfect, you have a new piece of code to reference, build off of, and even re-prompt to improve. It doesn’t even touch your source code, so \(a\) is very small.
For these reasons, it’s no surprise that users gravitate toward chat. But eventually, they need to actually edit source code. One affordance that has been successful is “Edit” (cmd/ctrl+I), where users can highlight code, press cmd/ctrl+I, type their instructions to transform the code, and have the diff streamed directly into the editor. While this is excellent for quick edits where you are confident that the LLM will succeed, the cost of failure is reasonably high: it clutters your editor with unsatisfactory code. [2]
Apply is important because it allows users to begin in the safe environment of chat and then bridge code to the editor when they are ready. By the time they touch source code, there is confidence in the quality of the changes.
Ways to implement Apply
The Apply problem can be phrased as “given a pre-existing file, and a draft of an edited version of the file, generate the full edited file”. There are many ways to achieve this.
Full rewrite
The most basic option is having the LLM rewrite the entire file. It’s simple and exactly what LLMs are trained to do, however when only 1 line in a 1000 line file has changed, it’s much slower and more expensive than it could be.
Apply-time lazy rewrite
A “lazy” rewrite is our name for when the model write a comment like // ... rest of code here .... Many foundation models appear to have been trained to output these comments in a predictable fashion.
Instead of rewriting the entire file, we could ask the language model to rewrite only what changed, using lazy comments to indicate where the rest of the code goes. As it streams, we can find the corresponding code from the original file and replace the lazy comments.
This is a fairly complex solution and introduces some chance of failure to correctly parse/replace the lazy comments. And it still requires a language model while applying.
Speculation
Speculative decoding is an inference trick where a smaller model is used to predict the next tokens (draft tokens) and a larger model follows behind checking its work. This allows much faster inference with provably equivalent quality.
Speculation also works if you generate draft tokens by some means other than a smaller language model. In the case of applying code to a file, most everything will remain the same, so the draft tokens can literally be a portion of the original file.
Though it still requires a language model, speculation doesn’t introduce any chance of parsing failure. The bigger problem is that many LLM APIs don’t support speculation out-of-the-box, so Continue users that bring their own API keys wouldn’t be able to use it.
Fine-tuned Apply model
Apply is a significantly easier task than writing the initial code, which makes it fairly obvious that a smaller language model could do the same task. Continue already has the option to select a smaller model (like Claude Haiku) for use in Apply, but a model trained specifically for the task might perform even better on the size vs. quality frontier. Still, this requires an LLM and, for local-first users, it adds an additional set of parameters to load into very limited memory.
Chat-time lazy edits + instant apply
In the end, we chose to take this route. While I’ll explain the inner workings below, the reason we chose this is:
- It is instant, rather than requiring an LLM to apply
- The “lazy” comments are actually a nice UI in chat, otherwise the LLM will repeat a lot of unnecessary code [3]
- It doesn’t depend on model or API provider, so it will eventually work for all users of Continue
Instant Apply
Let’s see how it works in the example of the GIF at the top of this post. This was the original file:
import { CheckIcon } from "@heroicons/react/24/outline";
import styled from "styled-components";
import { defaultBorderRadius, vscBackground, vscForeground } from ".";
interface CheckDivProps {
title: string;
checked: boolean;
onClick: () => void;
}
const StyledDiv = styled.div<{ checked: boolean }>`
display: flex;
flex-direction: row;
align-items: center;
justify-content: center;
padding: 0.5rem;
border-radius: ${defaultBorderRadius};
cursor: pointer;
border: 1px solid ${vscForeground};
color: ${vscForeground};
background-color: ${vscBackground};
&:hover {
background-color: ${vscForeground};
color: ${vscBackground};
}
width: fit-content;
margin: 0.5rem;
height: 1.4em;
overflow: hidden;
text-overflow: ellipsis;
`;
export default function CheckDiv(props: CheckDivProps) {
const { title, checked, onClick } = props;
return (
<StyledDiv onClick={onClick} checked={checked}>
{checked && <CheckIcon width="1.4em" height="1.4em" />}
{title}
</StyledDiv>
);
}
Step 1) Ensure “lazy” formatting at chat time
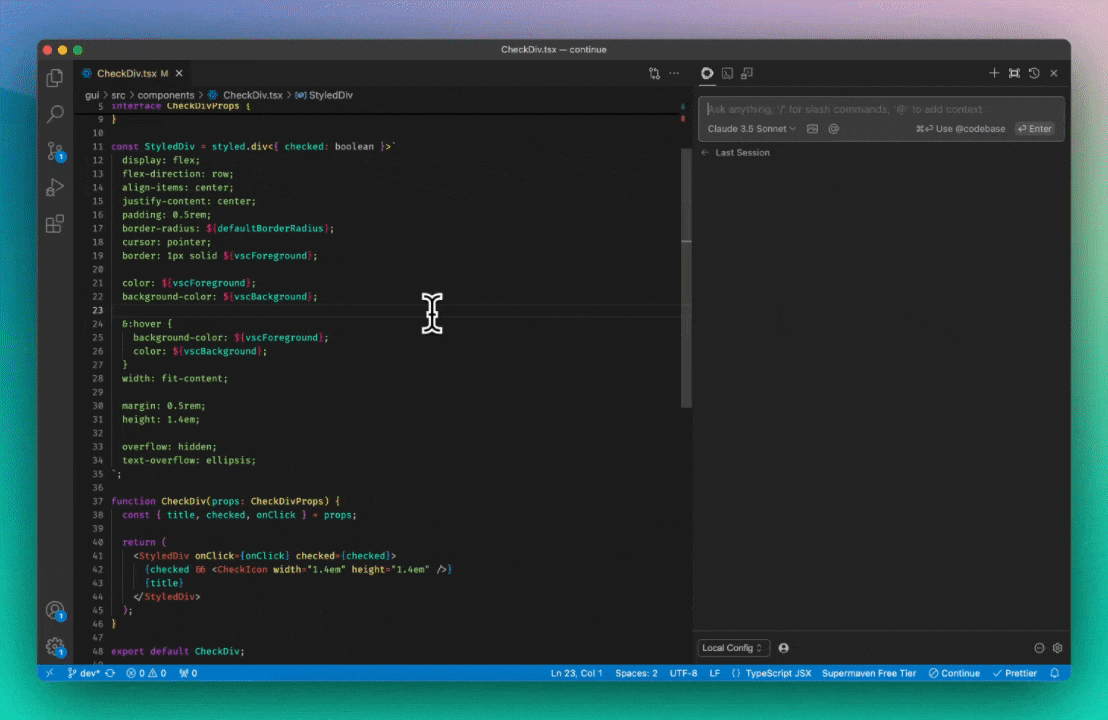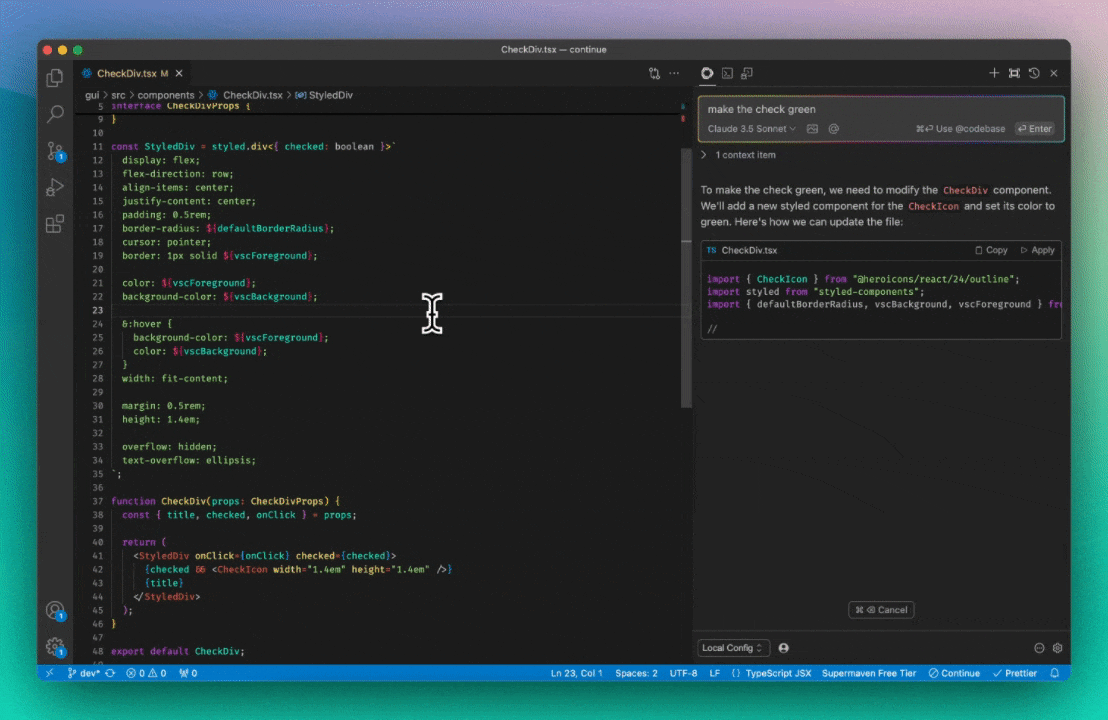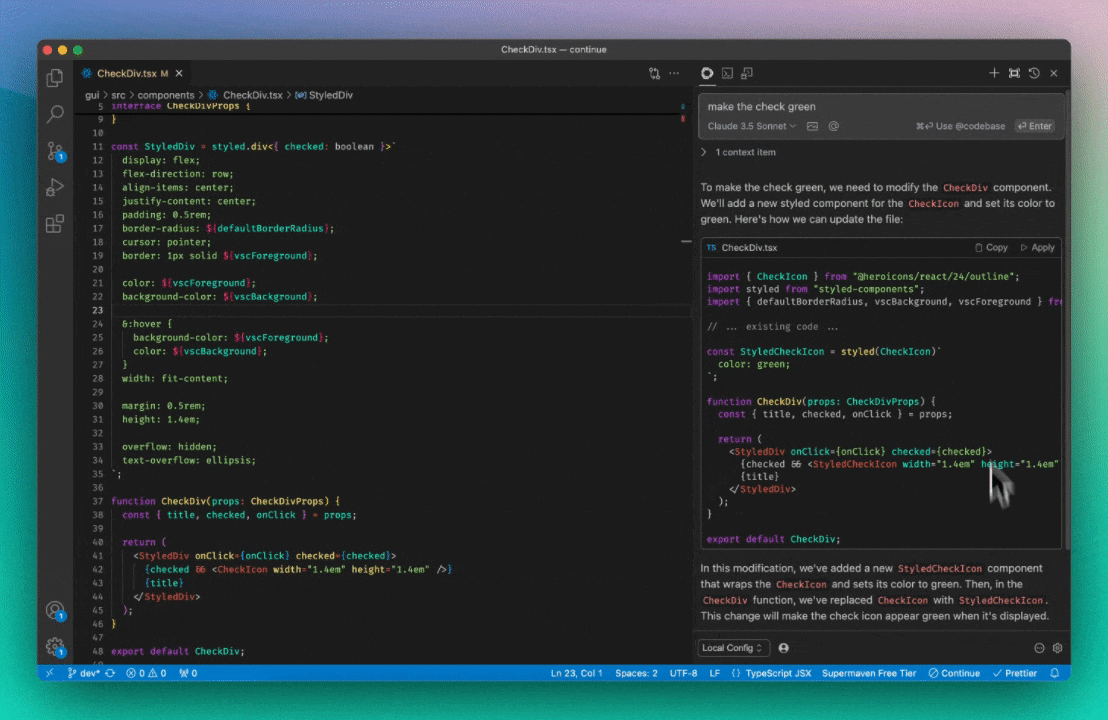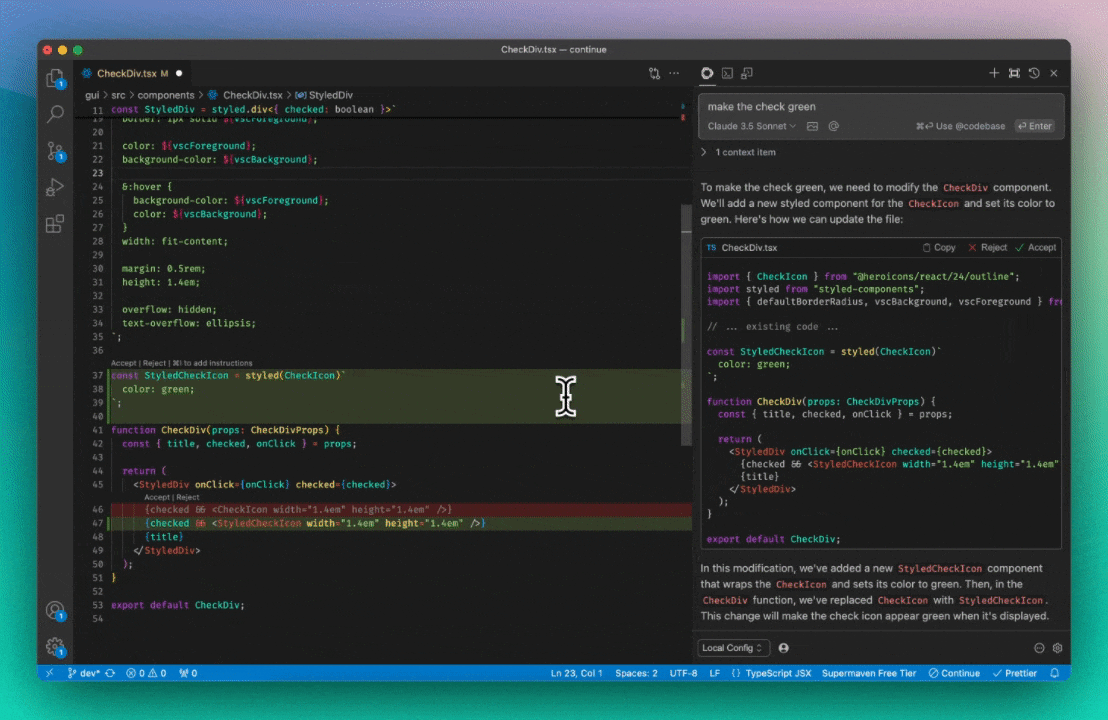
First, we give a system prompt to the LLM for all chat messages so that it knows to output “lazy” comments whenever it is editing a piece of code. These have to follow a particular structure such that no code is unaccounted for. In this example, the LLM generates the following, successfully saving tokens by not repeating CheckDivProps and StyledDiv:
import { CheckIcon } from "@heroicons/react/24/outline";
import styled from "styled-components";
import { defaultBorderRadius, vscBackground, vscForeground } from ".";
// ... existing code ...
const StyledCheckIcon = styled(CheckIcon)`
color: green;
`;
export default function CheckDiv(props: CheckDivProps) {
const { title, checked, onClick } = props;
return (
<StyledDiv onClick={onClick} checked={checked}>
{checked && <StyledCheckIcon width="1.4em" height="1.4em" />}
{title}
</StyledDiv>
);
}
Step 2) Find replacements for all “lazy” comments
We now have a representation of new version of the file, we just need to fill in the “lazy” comments with their counterparts in the original file. To do this, we convert the old and new files to their abstract syntax trees (ASTs) and perform a search. I’ll walk through the algorithm step-by-step for our example here.
On the left side, we have the top-level nodes in the original file (A = imports, B = CheckDivProps, C = StyledDiv, and D = CheckDiv), and on the right side we have the top-level nodes in the new file (E = StyledCheckIcon), with ... representing the lazy comment:

At each step, we will try to find the first match for the node on top of the left stack. At first, this is A, and we immediately have a perfect match in the new file. This means nothing has changed, and we will pop them both off of the stack.

Now, we look for a match for B. There isn’t one, but we have this “lazy” comment at the top of the right stack, which means that we will just absorb it into this, assuming that it was meant to stick around unchanged.

Next, we do the same thing for C.

Finally, for D we have a match with D'. How a match is determined is a deeper question, but in the example here, it is fairly clear that both instances of export default function CheckDiv(props: CheckDivProps) are referencing the same thing.
Now that we’ve found a match, we have moved beyond the “lazy” comment in the new file, and pop this from the right stack.
We also notice that there is a node unaccounted for before the match in the right column: this means it is new! But since it’s already accounted for in the new version of the file, we don’t have to do anything extra.

Finally, we are left with just the original function and its newer version. If there were any “lazy” comments within D', then we would recurse, but in this case we can just pop them both off of the stack and end.
Step 3) Generate diff with original file
At the end of this, we’ll have a list of the replacements for the lazy blocks that can be used to reconstruct a full representation of the new file. This is diffed with the original, and displayed in the editor for the user to review.
Notes
[0] If I had to guess, there’s an official phrase for this in the product design world
[1] Risk will be an even more difficult question for models like o1 because they take a variable amount of time to respond
[2] Though giving the opportunity to re-prompt reduces this risk, something we’ve recently improved
[3] This has typically been very much not true, but the reason for that is when you’re stuck copy-pasting, you do need the entire file to be rewritten. With an Apply button, that’s not necessary. Better to save tokens and time spent reading.