
Instant Apply with Relace

With guest author Eitan Borgnia
Frontier models like Claude 3.7 are becoming unbelievably strong coders, but they're also slow and expensive. They generate text at ~100-200 tokens/sec and can cost upwards of $15 per million output tokens.
When you use frontier models to implement edits to your codebase, you're often paying premium rates for both valuable changes and unchanged sections alike. Instant apply is about the separation of these concerns -- use heavyweight frontier models for the new sections of code, and use a lightweight apply model to merge the new into the old.
Let's take a look at the philosophy behind the Relace instant apply model, and why it deserves a place in your Continue model hub.
Working with LLM Laziness
Models instruction-tuned to adopt the assistant persona, are known to be lazy for code generation tasks. Instead of writing the full code, LLMs tend to replace large sections of unchanged code with comments like // ... keep rest of code unchanged. It's a behavior stemming from the nature of training data on websites like Stack Overflow, and the strict limitations on output sequence length (usually 8192 tokens).
This was annoying when the dominant workflow involved copy/pasting code to and from the ChatGPT web UI, but it's a total show stopper for automated agentic coding systems. Of course, you can always yell at the model in your prompt with something like: DO NOT TRUNCATE CODE OR YOU WILL BE FINED. This can work, especially with modern models, but it's still an inefficient use of resources.
Instead, we can use this laziness to our advantage by training a small, much faster LLM that merges the truncated edits into the original code. [1]
Why Is Merging Hard?
A natural question is: Why do we even need an LLM to do the merge -- can we not write an algorithm to deterministically merge the lazified LLM output?
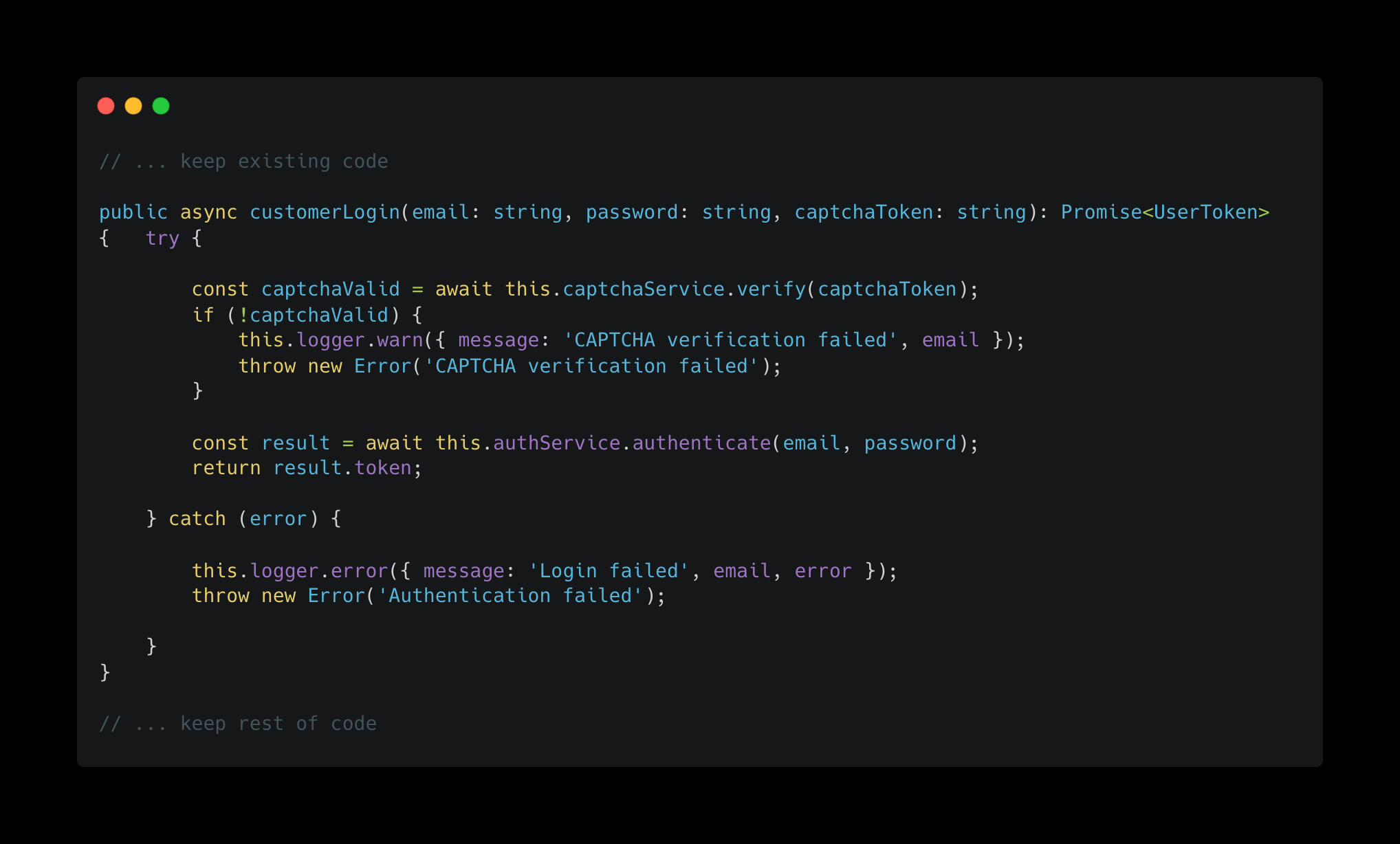
Here's an example that shows why it's difficult to write a general algorithm for this. Say we have the following login function within a file that handles auth.
Suppose a user prompts the frontier model to: "Rename userLogin to customerLogin and verify that the captcha is passed before allowing the customer to log in."
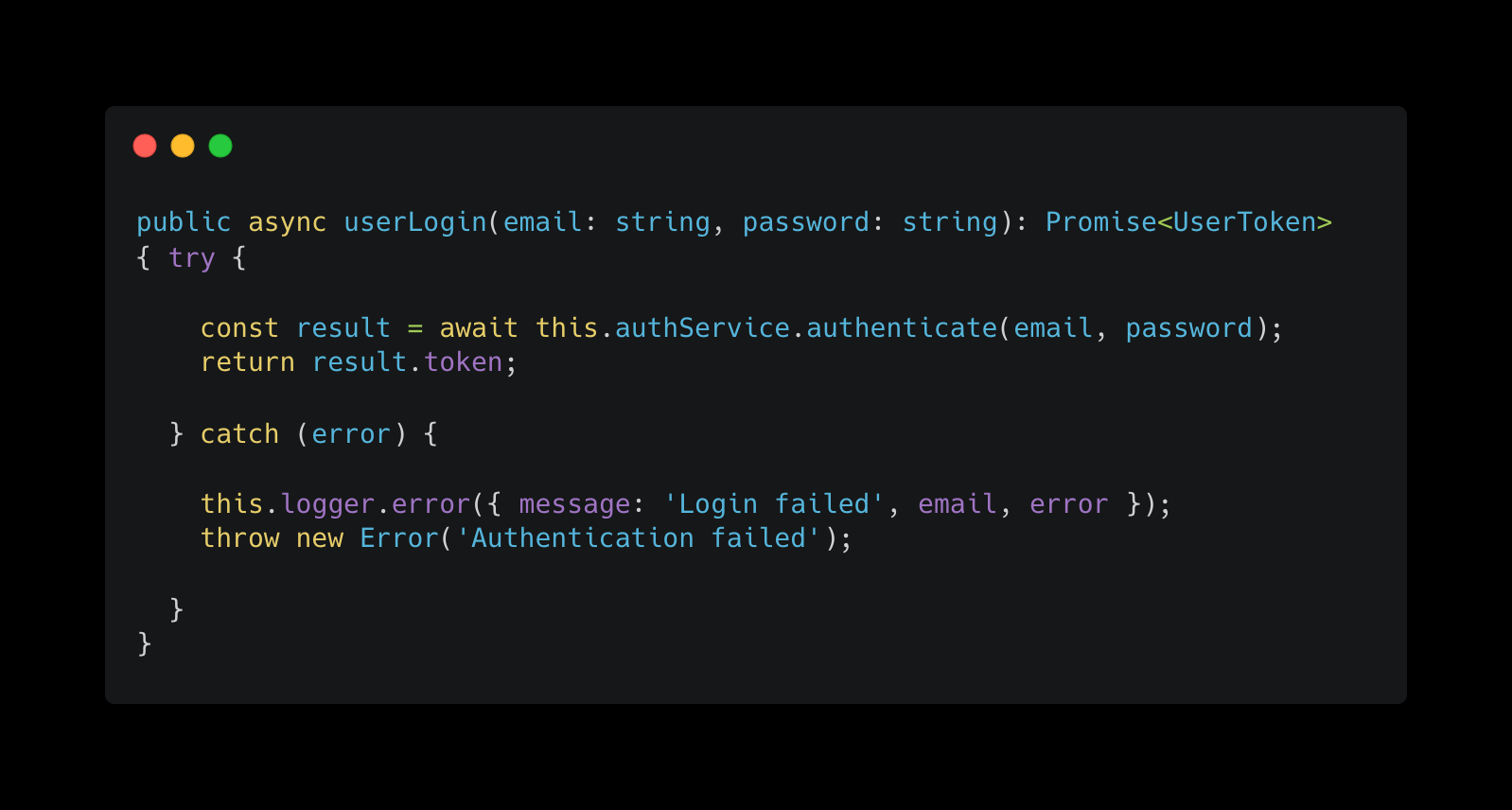
A corresponding edit snippet from Claude might look like this.
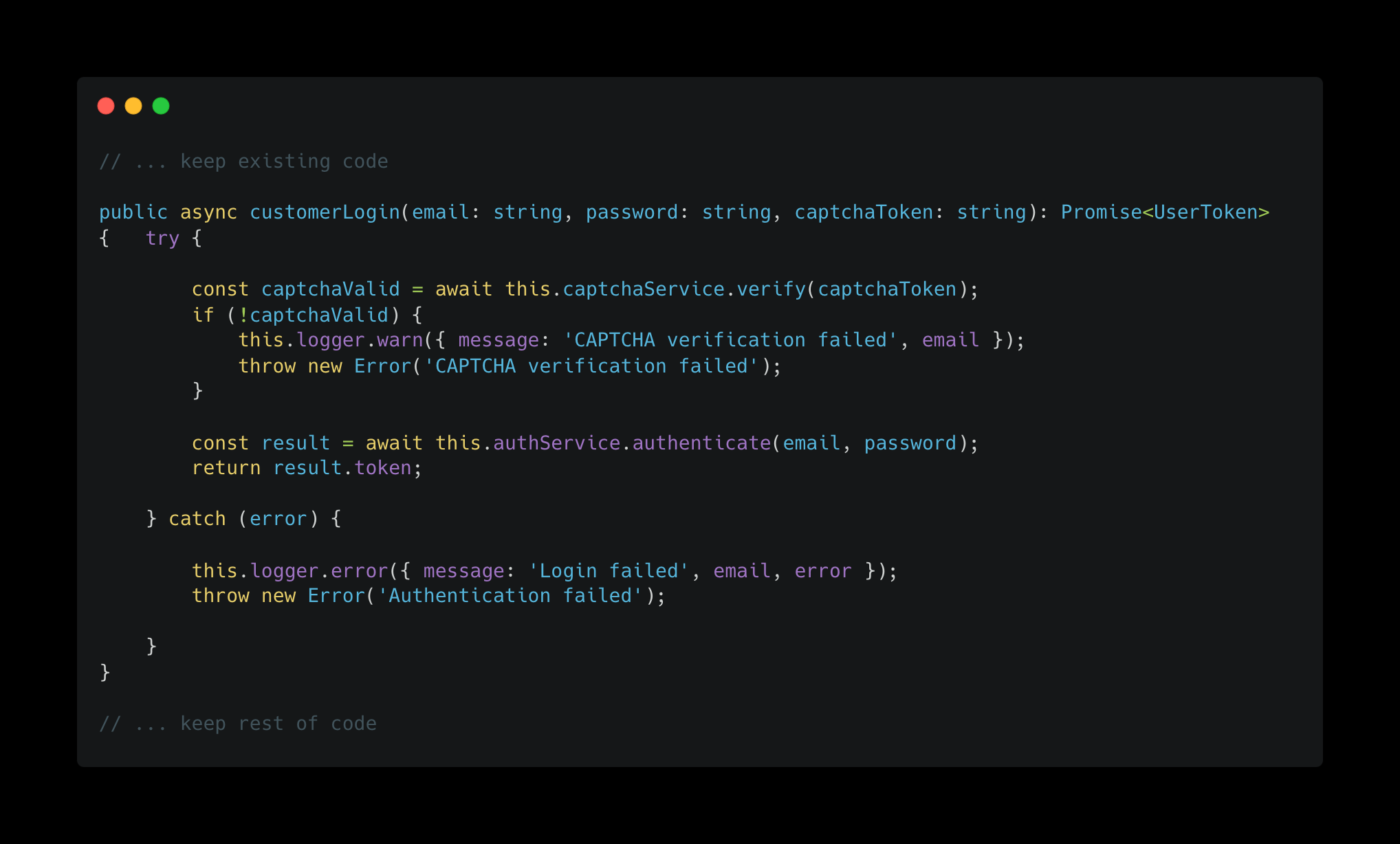
In this situation, you can see the challenge of writing a generalized algorithm that would correctly replace userLogin with customerLogin. The name of the function has changed in addition to the body, and most simple merging algorithms would end up adding the customerLogin as a new function.
You could, in theory, prompt the model to include the requisite information in the comments that makes the deterministic merge possible. However, this starts to creep into the territory of structured diff formats, which have their own sets of challenges.
LLMs Aren't Used to Diffs
There's a lot of evidence showing LLMs generate lower quality code when they are forced to simultaneously think about formatting the output correctly. Aider did a comprehensive study for outputs structured as JSON, and a Taiwanese research group investigated the effects with a variety of more unusual formats.
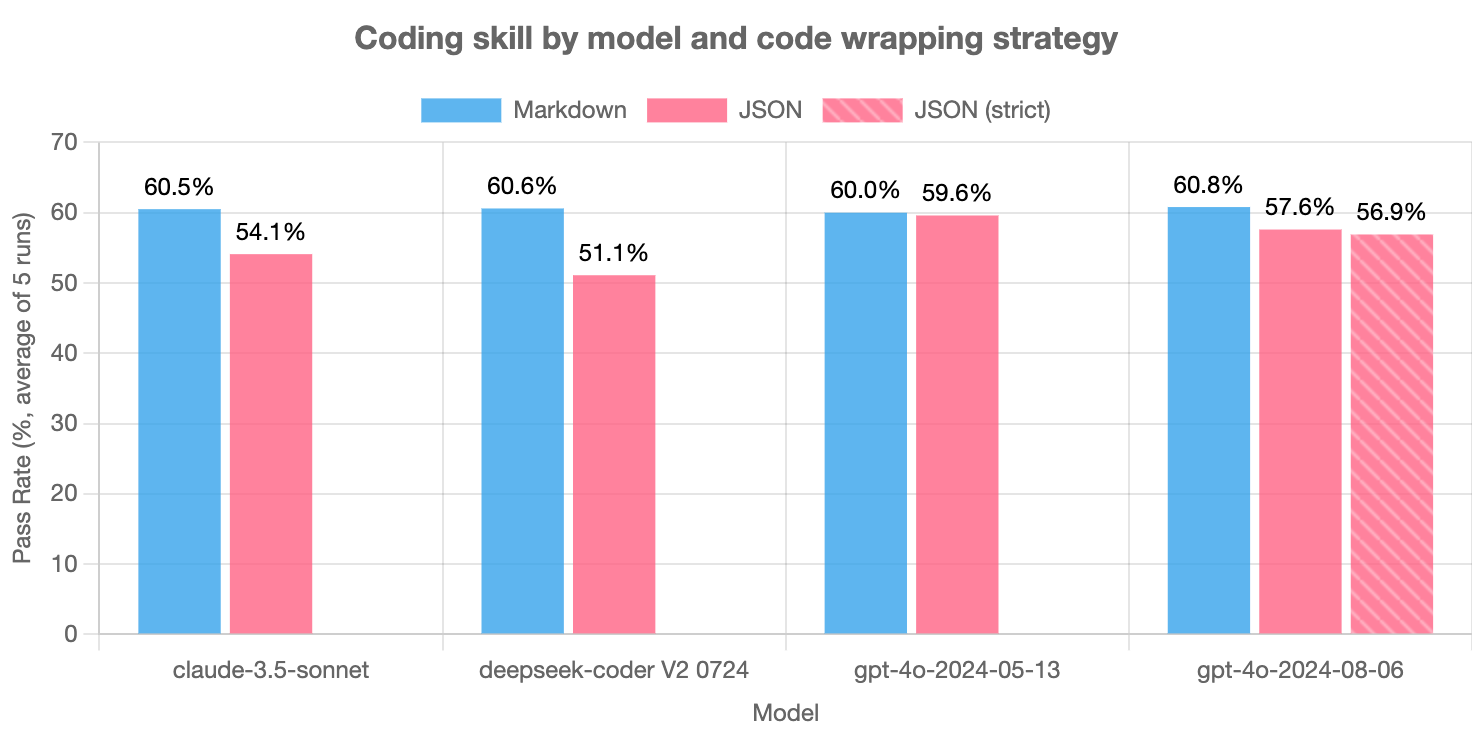
A common strategy for reducing the token budget on edits is to use a search/replace or uDiff format, which can then be deterministically merged. The problem is frontier LLMs aren’t explicitly optimized for these structured formats. There is some evidence from Aider that the uDiff format is encountered enough in pretraining to retain performance on code generation. However, it's pretty clear that models prefer the less rigid lazy format and generate it more reliably -- search/replace methods with average failure rates of >10% drop to <2% when switching to lazy ouputs + apply.
Moreover, these structured diff formats are still relatively token inefficient. Having to specify all added/deleted lines explicitly with uDiff or writing find blocks in search/replace requires 1.5-2x more tokens than the lazy outputs.
By working with the model's natural tendencies to produce lazy edits and using a thin layer of intelligence from a specialized apply model, we can achieve consistently higher quality, faster, and cheaper results.
Relace Instant Apply
Relace's instant apply model is trained on a large dataset of examples with initial code, lazy edit snippets, and correctly merged final code across dozens of common programming languages. The wide variety of lazy LLM outputs it sees during training makes it very robust to edge cases in production at ~98% accuracy.
It's deployed using an optimized speculative decoding algorithm to achieve speeds of over 2000 tokens/second, and it's getting better with each release. You can read more about speculation on our original post about instant apply from October.
Additionally, to play around with the model and see some examples of the merges it can perform, check out the playground at app.relace.ai. Happy applying!
[1] Weaker language models from late 2022 and early 2023 were lazy in a more problematic way -- they would neglect to implement important functions entirely. Here we refer to the modern laziness of stronger LLMs, where the model doesn't write entire code for sections that remain unchanged.