
Morph: Faster Apply + Better Retrieval


Today we have a guest post from Tejas at Morph.
Stop Fighting with AI Code Edits
You ask Claude to refactor your authentication logic. It responds with 80 lines of beautiful code.
Now what?
Copy the whole thing? Manually find where each piece goes? Watch your indentation break?
This is the hidden bottleneck of AI coding. The back-and-forth. The friction. The context switching that pulls you out of developer flow state. Reliable, fast edits are fundamental to any top-notch AI coding agent.
The Problem with AI generated code
Watch what happens when you try to apply AI-generated code today:
# Claude gives you this:
// ...existing code...
def authenticate_user(email, password):
"""Updated authentication with rate limiting and better security"""
// ...existing code...
token = await auth.user()
return token
# You have to:
1. Find the original function (where was it again?)
2. Select exactly the right lines
3. Paste without breaking indentation
4. Hope you didn't miss any imports
5. Fix the inevitable formatting issues
Result: 15% of the time, something breaks. 100% of the time, you've lost your flow.
What's an Apply Model?
An apply model is dead simple: It takes your original code + AI suggestions and merges them perfectly. Every time.
Think of it like this:
- Without apply model: You're the copy-paste middleman
- With apply model: The AI edit just... happen
Why Lazy Diffs > Structured Formats
Here's the insight: Models like Claude don't naturally think in diffs.
Forcing them to output perfect patch formats is like asking a chef to describe a recipe in IKEA instructions. It's unnatural, error-prone, and limits what the AI can accomplish and biases it towards basic edits.
Instead, let Claude write naturally. Let a specialized model handle the merge.
The numbers:
- Structured diff format: 25%+ failure rate
- Lazy diffs + Morph Apply model: <1% failure rate
- Bonus: 1.5-2x more token efficient
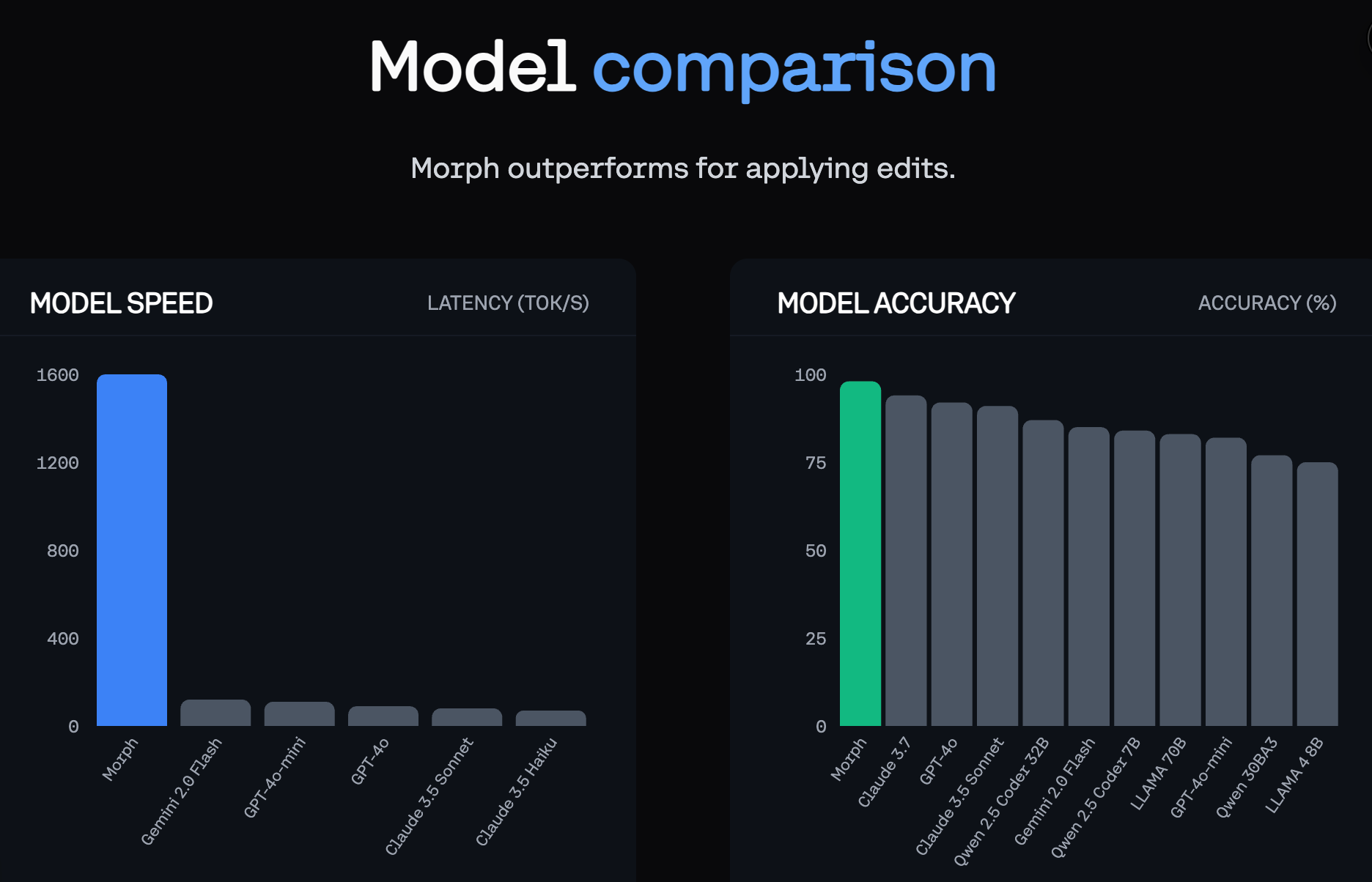
Speed = Flow State
Morph Apply: 1800+ tokens/second
Why does this matter?
- Without Morph: 30s full rewrite or 25% broken diff apply → You lose focus
- With Morph: <2s apply → You stay in flow state
When your tools are instant, you stop thinking about tools. You think in pure logic. No more low-intent keystrokes.
You stay operating at the abstraction level where you're most powerful - which is what Continue enables - letting devs think on hard, useful problems, and automating the rest.
The Complete Toolkit
Apply models handle the writing. But what about reading your codebase?
Morph Embeddings: Find the right code to edit Morph Reranking: Surface the most relevant context Morph Apply: Merge changes perfectly
One API key. Three models. Zero friction.
The Technical Magic (For the Curious)
How do we hit 1800+ tokens/second?
- Custom speculative decoding - Predict likely merges
- Fused CUDA kernels - Hardware-level optimizations
- Trained specifically for code merges - Not a general-purpose model doing a specific task - our model is ONLY good at merging code
Get Started in 30 Seconds
yaml
# Add to your Continue config:
models:
- uses: morphllm/morph-v2
with:
MORPH_API_KEY: ${{ secrets.MORPH_API_KEY }}
The bottom line: Every second you spend fixing apply errors or copy-pasting is a second you're not solving real problems.
Fast applies aren't just about speed. They're about keeping you in the zone where you do your best work.