
Root path context: The secret ingredient in Continue's autocomplete prompt


If you interpreted “root path” as the root directory of your computer, don’t worry! Continue wants nothing to do with this. What we’re going to share is our strategy for gathering (and caching) autocomplete context, which relies heavily on the root path: the path from a node in the syntax tree to its root. This allows Continue to seemingly understand your entire codebase while only actually reading a fraction.
Measures of Proximity
A core challenge in much of our work is determining the most relevant context to pass to the language model. One way to think about relevancy is “proximity” to the user’s request, where several meanings of “proximity” might be considered:
- Proximity in time (to include recently edited files)
- Proximity in latent space (determined by the dot product of embeddings)
- Proximity in the code graph (to include code definitions that are used by surrounding variables)
- Proximity in the abstract syntax tree (AST) (to reference parent or sibling nodes in the tree)
For Autocomplete, we care a lot about giving snappy responses (low 100s of ms). And because the scope of code being generated is typically small (≤ a few lines), we don’t need the entire codebase in context; only a small part of it is relevant. This means that we optimize for a smaller number of input tokens, sourced with as much precision as possible.
With this in mind, proximity in latent space isn’t a great option. Calculating an embedding and searching a potentially large index on each keystroke isn’t very performant, and from a precision standpoint this strategy is even less likely to be useful.
Proximity in time may be useful, but users might often have recently opened 5 or more files, and each of them may contain thousands of lines of code. Recently edited ranges are another possible strategy, one we’ll likely cover in a future post, but still not guaranteed to be relevant.
The two remaining measures of proximity (in the code graph or the AST) turn out to be quite useful for the autocomplete use case. Type definitions, function headers, parent classes, or other nearby code symbols very frequently contain exactly the information needed to accurately write out a few lines of code. And because of the structure offered by the AST and tools like the Language Server Protocol (LSP), we can find this information without resorting to guessing.
With a precise source of context in mind, we need only to solve a couple of problems: 1) how to determine which definitions are most relevant and 2) how to make it fast.
Root path context, in theory
Just to refresh, the root path is the set of nodes in the AST that lie between the node containing the position of the cursor and the root node. The core observation that we lean on for gathering context is that all nodes along this path may contain relevant information. Take the following code for example:
import convertToAllCaps from "./util";
import convertToAllLowercase from "./util";
type CapitalizationType = "all-lowercase" | "all-uppercase" | "default";
class Person {
name: string;
age: number;
constructor(name: string, age: number) {
this.name = name;
this.age = number;
}
celebrateBirthday() {
this.age++;
}
/**
* Log "Happy {age} birthday {name}!" in desired casing
*/
sayHappyBirthday(capitalizationType: CapitalizationType) {
// [CURRENT CURSOR POSITION]
}
}
The cursor is currently located inside of a method (sayHappyBirthday), inside of a class (Person), inside of a file (Person.ts). Each of these nodes contains useful information, and the thing that they all have in common is that they lie on the path between the root of the tree and the current position of the cursor.
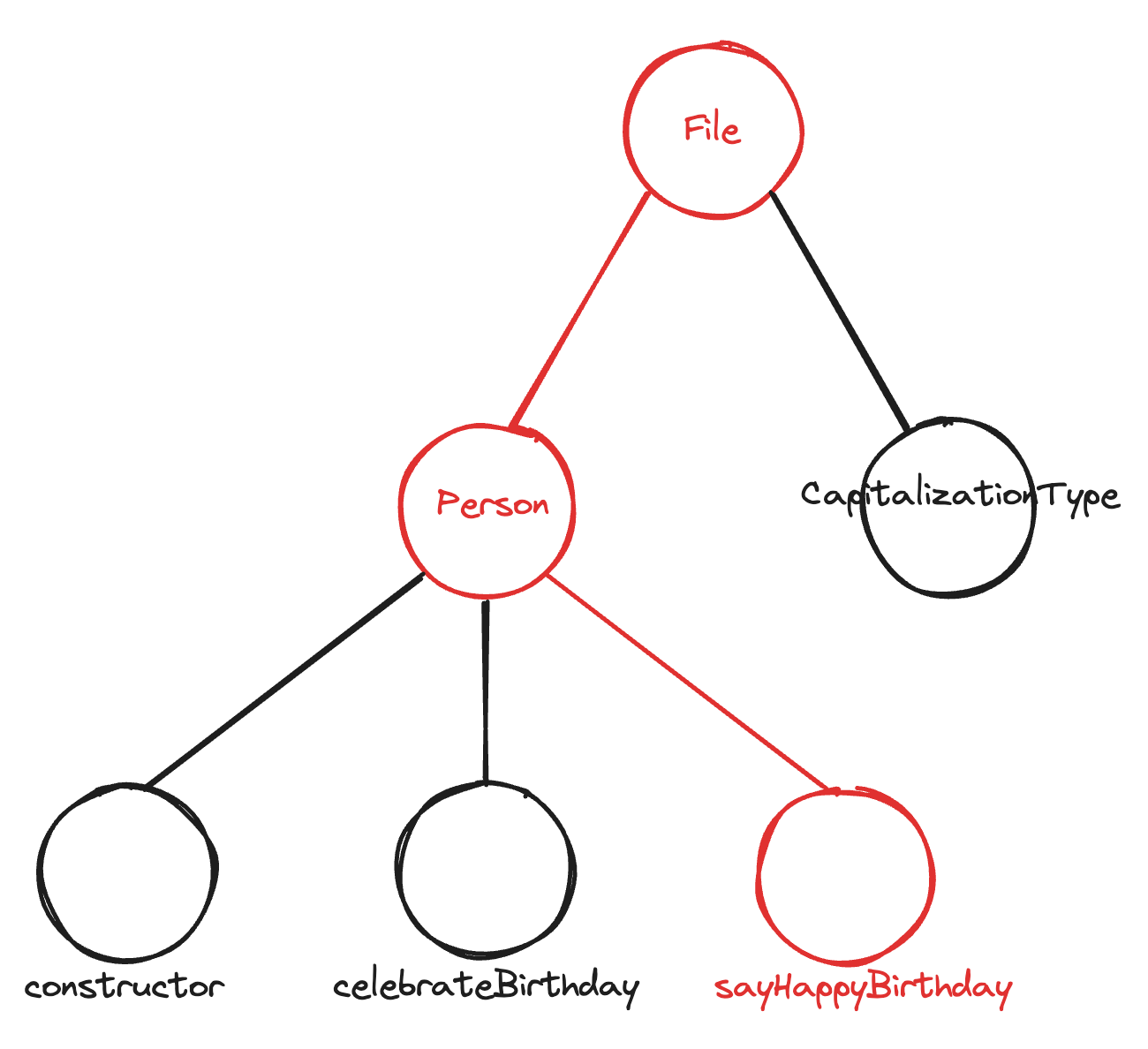
By using the simple heuristic of accumulating context along this path, we are able to gather all of the information needed to make this completion:
- The definition of
CapitalizationTypeis found by resolving the type definitions of all parameters of thesayHappyBirthdaymethod. - The
nameandageattributes are found by resolving top-level attributes of thePersonclass. - The definitions of the
convertToAllCapsandconvertToAllLowercasefunctions are found by resolving the imports at the top of the file.
Though this is obviously a toy example [1], it demonstrates a very useful heuristic that resembles the way developers navigate code: we have an intuitive sense for our location in the file+syntax tree, and use this in combination with “go to definition” to understand the code around us.
In Practice
To turn this idea into working code we take the following steps:
- Parse the file using Tree-sitter to get the AST
- Starting at the root and descending to the node of greatest depth that contains the position of the cursor, record each node along the way [2]
- For nodes of certain important types (like functions, classes, and the file root), run a Tree-sitter query to get the locations of important sub-nodes (often type annotations)
- Use the LSP to “go to definition” for each sub-node, recursively resolving type definitions
For example, in the sayHappyBirthday method, we will query to find the CapitalizationType parameter, and then use “go to definition” to find its source. Now the line type CapitalizationType = "all-lowercase" | "all-uppercase" | "default"; will be included in the prompt.
Making it fast
A problem with relying on the LSP to “go to definition” is that we have little control over responsiveness. The LSP implementation for each programming language is maintained by a separate group of developers, may be more or less performant in large codebases, and this may be exacerbated if we are making requests on each keystroke, causing significant lag.
Luckily, this context-gathering strategy is easily amenable to caching. Say we now want to make some changes in the celebrateBirthday method (certainly abstractions to allow aging in reverse wouldn’t be premature).
Up through the lowest common ancestor, we have already done the work (Tree-sitter query and LSP requests) for each node. So the only requests required will be for the celebrateBirthday method.
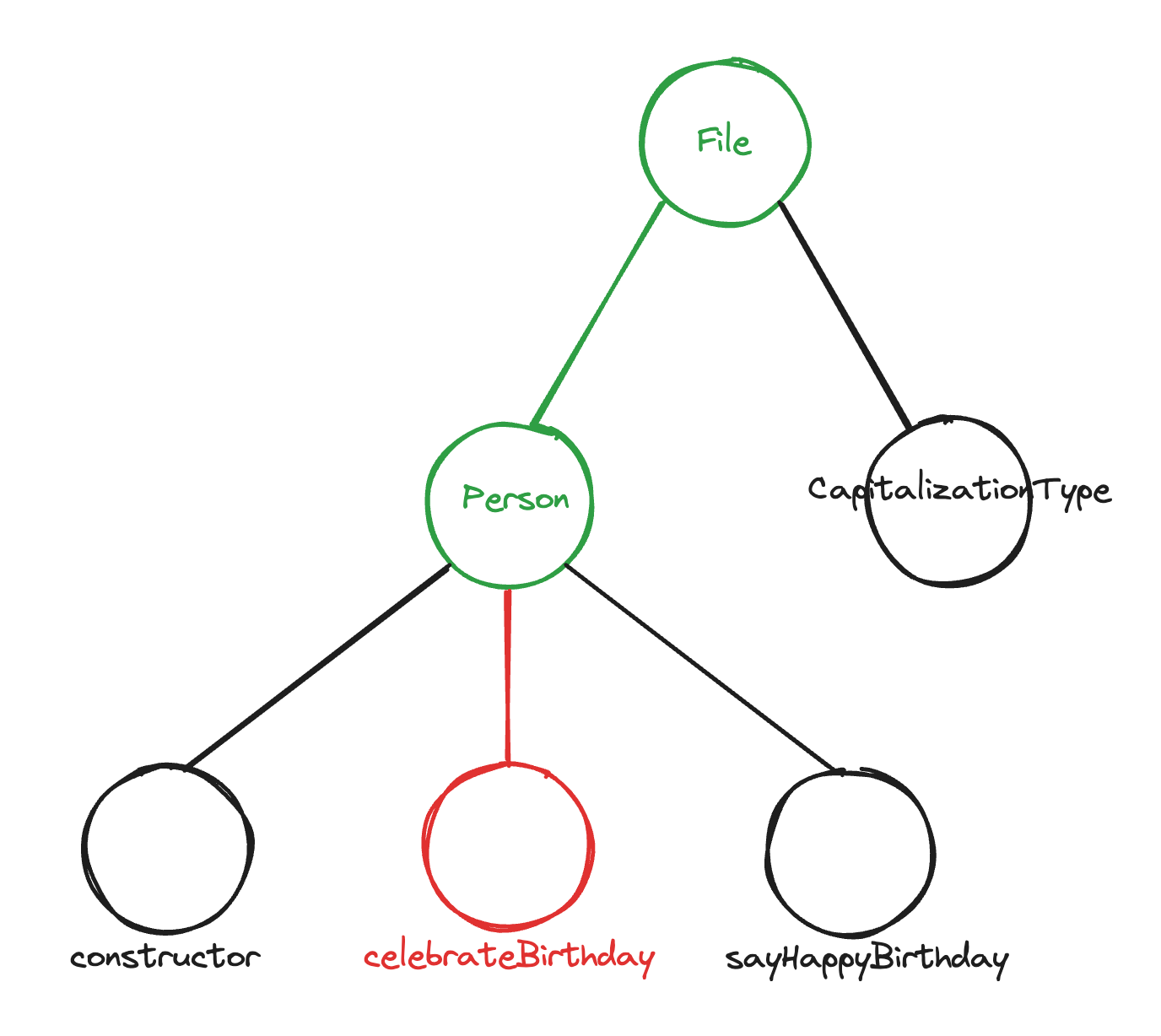
Implementing this doesn’t have to be difficult. A flat cache of the N most recent LSP requests will give a high cache hit rate because of the point made above: even when skipping around in a file, a large part at the top of the root path is probably static. If not, or if we switch files, we’re only adding O(log(size of AST)) extra nodes.
What’s next
We’ve started rolling out root path context, but there are still lots of improvements to make.
First, Tree-sitter queries need to be manually written for each language, and we’ll be expanding our support from 5 of the most common languages to dozens.
We’ve yet to implement any method of revoking context from the cache. Since recent changes are often relevant, we’ll want to make sure that we aren’t including outdated type definitions.
Finally, another benefit of this structure is that it can easily be prompt cached. As long as we include context in order from the top of the AST to the bottom, a large portion of the start of the prompt will be unchanged across calls.
If you’d like to know more, you can read the autocomplete documentation or check out the original source code here (it’s surprisingly concise!).
Notes
[1] Because the file is small this context would already be included by default in the prefix. However in a larger file, or if we needed to resolve more types which were defined in other files, the default doesn’t work.
[2] Not always a leaf node when the cursor is located in whitespace between code symbols
[3] Before deciding to just call it what it is (root path context) we, with Continue’s assistance, attempted acronyms:
ASCENT: Abstract Syntax Context Extraction for Node Traversal
CLIMB: Context Lookup through Iterative Method of Branching
UPROOT: Upward Path Retrieval for Optimized Object Tracing
LEAF: Lexical Environment Acquisition Framework
BRANCH: Bottom-up Retrieval of Abstract Node Contexts Hierarchically
STEM: Syntax Tree Exploration Method
TRUNK: Tree Reconciliation for Upward Node Knowledge
CANOPY: Context Acquisition through Node Optimization Pathing Yield
ROOTS: Recursive Obtainment Of Tree Semantics
ARBOR: Abstract Representation Based Object Resolution