
Is it still necessary to tune an LLM preset? Tracing the history of temperature, penalty, and sampling schemes

Introduction
These days, every large language model (LLM) roughly comes with the same settings, which can be adjusted by the user:
- temperature
- penalties: presence penalty, frequency penalty / repetition penalty
- schemes: top-k, top-p
In r/LocalLlama, users will tell you the tale of how the Oobabooga Preset Arena gave us the Divine Intellect (a model preset), and that this is what you should use. But do you actually need to bother with changing the default settings of an LLM?
To figure this out, we go back in history to understand how and why presets evolved as language models got larger and new open-source models emerged.
LLMs predict one token at time. Before the next token is predicted, there is a probability that each token in the training data vocabulary will be predicted. However, the actual candidate pool that is sampled from for prediction is usually limited to a much smaller size than all possible tokens and the probabilities are often adjusted in an effort to make the generated text more coherent and diverse.
Temperature, penalties, and sampling schemes form the model preset, which enables you to adjust the candidate pool for sampling and probabilities for each token at prediction time. Here is how that preset came to be...
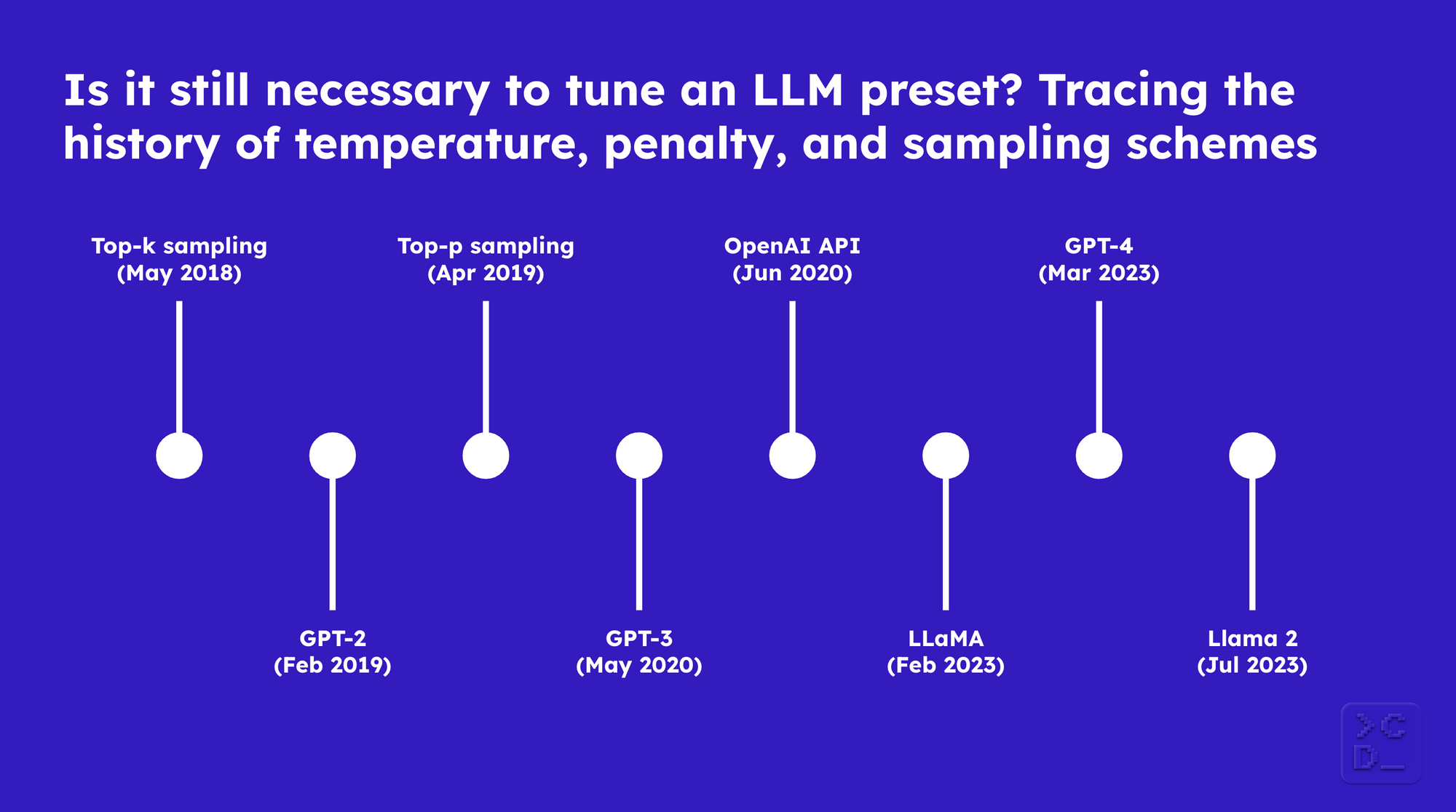
Top-k sampling (May 2018)
Facebook AI Research published this paper in May 2018, which used the top-k random sampling scheme. At the time, language models were prone to paying little attention to the prompt. The top-k parameter was introduced to address issues with previous sampling strategies producing common phrases and repetitive text from the training set. It works by only sampling the next token from the top 'k' most probable tokens, where 'k' is an integer you set beforehand.
GPT-2 (February 2019)
OpenAI published this paper on GPT-2 in February 2019, which generated surprisingly high quality passages like this one on Ovid’s Unicorn. The top-k sampling scheme was part of the preset. When the model was released, temperature and repetition penalty were also part of it. Temperature is used to make the model more or less likely to predict less probable tokens, while the repetition penalty is used to make the model more or less likely to predict the same line verbatim.
Top-p sampling (April 2019)
Researchers at the University of Washington, Allen Institute for Artificial Intelligence, and the University of Cape Town published this paper a couple months later, which pointed out issues with top-k sampling and introduced an alternative: top-p sampling. Instead of limiting the sample pool for the next token to a fixed size 'k', top-p sampling allows you to set a cumulative probability threshold, so that the candidate pool for sampling can dynamically expand and contract. This decreases the model's tendency to produce gibberish in some situations without limiting the creativity of the model in other situations. In later versions of GPT-2, top-p sampling became part of the preset.
GPT-3 (May 2020)
OpenAI published this paper on GPT-3. Even though top-p sampling had become available in GPT-2, top-k was still mentioned by the authors of the GPT-3 paper.
OpenAI API (June 2020)
One month later, the OpenAI API was announced and some developers were given access to GPT-3 through it. In this API, repetition penalty was renamed to frequency penalty, temperature and top-p sampling remained the same, and presence penalty was introduced. The presence penalty is used to make the model more or less likely to talk about new topics. It's not clear exactly whether top-k sampling was ever possible via the API or when it would have been removed, but it definitely was not an option by June 2021.
LLaMA (February 2023)
Meta AI, formerly known as Facebook AI Research, published this paper on LLaMA and released it as an open-source model. It was not nearly as good as many of the commercial LLMs, but developers could play with it on their machines and began discussing their presets on the newly created r/LocalLLaMA. The same presets were generally possible as on the OpenAI API, except frequency penalty was often referred to as repetition penalty again, and top-k was included too.
GPT-4 (March 2023)
OpenAI published this technical report on GPT-4 in March 2023, and the OpenAI API had the same preset options as before. But GPT-4 was so good at generating text that changing the preset became less necessary for many use cases. By this point, many people were also using the model through the ChatGPT interface instead of the API, which does not give you the option to adjust the model preset.
Llama 2 (July 2023)
Meta AI published this paper on Llama 2 in July 2023. It was an improvement from the first generation LLaMA model, yet it still was not as good as commercial models like GPT-4. It can also exhibit issues like too much repetition, so tuning the preset remains important when using it.
Conclusion
You can often shape model responses more by using a different LLM, prompt format, and/or prompt content than adjusting the model preset. But if you have already optimized those, you can also consider changing the preset. Here are the questions you'll want to ask and answer to do that...
1. Do I want the responses from the model to be more likely to talk about new topics?
Increase the presence_penalty to get more variety in each response or decrease to get less
2. Do I want the responses from the model to be more likely to include the same line verbatim?
Increase frequency_penalty / repetition_penalty to get less repetition in each response or decrease to get more
3. Do I want the responses from the model to be more likely to include less probable words?
Increase temperature to make the responses more random or decrease to make them less random
4. Do I want the responses from the model to be more likely to only include the most probable words?
Increase top_p or top_k to make the responses more random or decrease to make them less random
If you liked this blog post and want to read more about DevAI–the community of folks building software with the help of LLMs–in the future, join our monthly newsletter here.