
Why we’re excited about prompt caching for engineering teams


Anthropic’s rollout of prompt caching, also known as context caching, follows similar offerings from providers like DeepSeek and Google and has been getting a lot of attention recently. At Continue, we're particularly excited about the potential impact on engineering teams, as prompt caching can significantly reduce costs and latency. However, to fully realize these benefits, teams need to align on what context to cache and how to cache it in their prompts.
How prompt caching works
When Large Language Models (LLMs) respond to your questions, they do so in two parts: processing input tokens and sequentially generating output tokens.
The same input tokens are often passed across multiple prompts to a model. For example, if you're using a prompt template with multiple examples or a lengthy system prompt, reprocessing this identical context for every request is wasteful.
This is where prompt caching comes into play. Prompt caching reduces the work of the first step—processing input tokens—by enabling developers to specify blocks of frequently used context to cache.
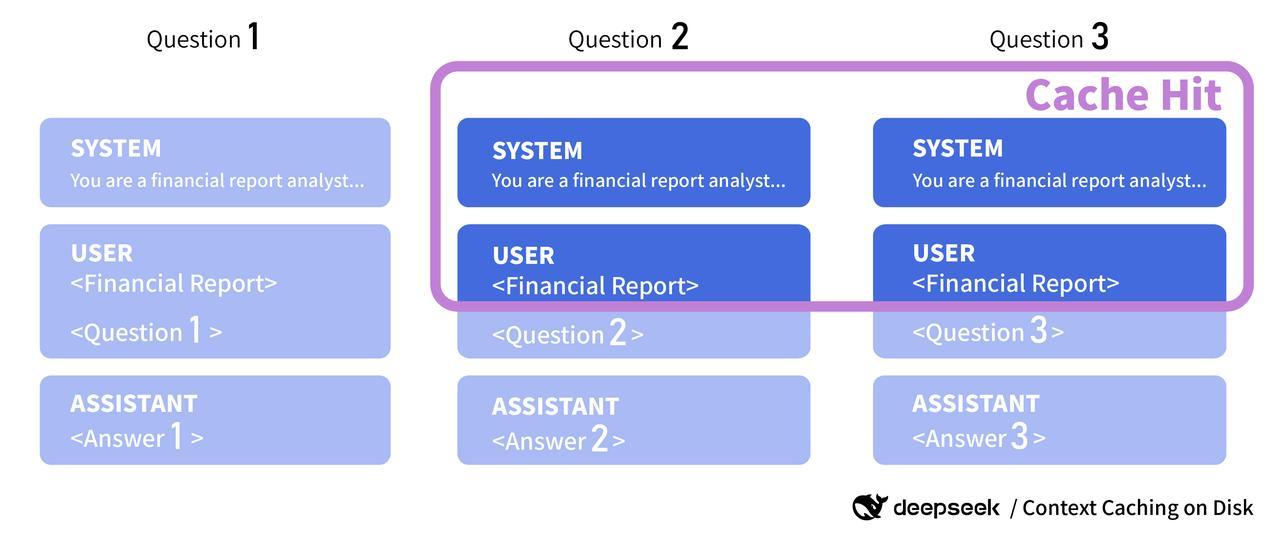
More precisely, it is not the actual context that is cached, but rather the state of the model after processing the given context. For prompt caching to be effective, it must be a perfect prefix match.
Use cases for coding assistants
So, we know that there are potentially significant cost and latency reductions through prompt caching. But what new use cases does this enable for end users of AI code assistants?
- Many-shot prompting: Including large example sets (10+) can be an efficient alternative to fine-tuning models. See this tweet by Alex Albert, DevRel at Anthropic, for more inspiration.
- Improved autocomplete and codebase retrieval: This can be achieved by passing along a “summary” of the top-level code symbols in your codebase, e.g. using a repository map.
- Talk to your docs: Not just snippets retrieved through semantic search, but the entire documentation set.
How to get the most out of prompt caching for your team
A key theme throughout all of the above examples is the need to align your team on a shared set of context to cache. If each developer is using a slightly different version of an example set, repository map, or documentation, you’ll miss out on the cost and latency savings from prompt caching.
At Continue, we've identified .prompt files as a powerful tool for achieving this alignment. Prompt files are an easy way to build and share prompts across a team, and include the ability to configure model parameters, set a system message, provide examples, and include additional context such as documentation.
Building a shared library of prompt files enables teams to standardize their approach to common tasks such as testing and code reviews, and to leverage cached prompts more effectively. By ensuring consistency in these areas, you'll increase cache hits, reduce costs, and minimize latency.
Try out prompt caching with Continue
As a first step, we’ve enabled support of prompt caching for system messages with Anthropic. DeepSeek performs prompt caching automatically, and we plan to rollout support for Google in the near future.
We’ve created a sample prompt that includes the Anthropic blog post announcement as a system message. You can download the prompt here, and add it to the .prompts/ folder in a project to use it.
Lastly, you’ll need to update your Anthropic model configuration with "cacheSystemMessage": true:
{
"models": [
{
// Enable prompt caching
"cacheSystemMessage": true,
"title": "Anthropic",
"provider": "anthropic",
"model": "claude-3-5-sonnet-20240620",
"apiKey": "YOUR_API_KEY"
}
]
}
To try it out, type /claude-prompt-caching into the chat panel, and then ask a question like “What is the input token pricing?”.
Special thanks to @BasedAnarki for contributing the initial draft of this work
Looking forward
Prompt caching is both most effective and most difficult to coordinate in teams.
As we look to the future, we're exploring a number of approaches to address these challenges. Promising areas of development include methods to integrate shared repository maps with local development changes, enhancing prompt files with user-specifiable cache blocks, and auto-caching for multi-turn conversations.